簡介
工具
演算法與實作
本演算法參考 粉丝日志 RHadoop实践系列 來實作,特別感謝有這種中文的教學文章。
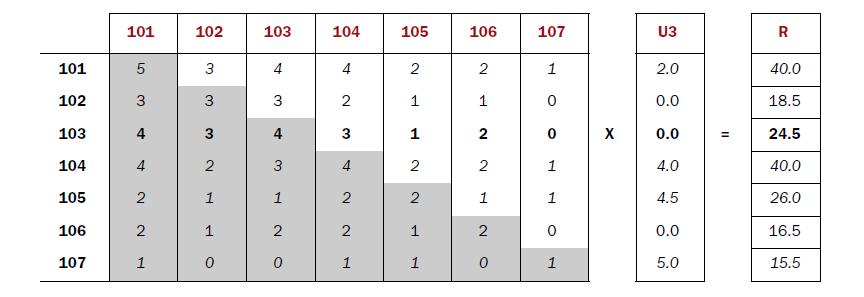
推薦結果 = 伴隨矩陣 (co-occurrence matrix) * 評分矩陣(score matrix)
map-reduce 實作步驟:
建立 item’s co-occurrence matrix,然後算出 frequence
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
train.mr<-mapreduce(
train.hdfs,
map = function(k, v) {
keyval(k,v$item)
},
reduce = function(k,v){
m<-merge(v,v)
keyval(m$x,m$y)
}
)
step2.mr<-mapreduce(
train.mr,
map = function(k, v) {
d<-data.frame(k,v)
d2<-ddply(d,.(k,v),count)
key<-d2$k
val<-d2
keyval(key,val)
}
)
2 . 建立 user 's 評分矩陣
1
2
3
4
5
6
7
8
9
10
train2.mr<-mapreduce(
train.hdfs,
map = function (k, v)
df<-v
key<-df$item
val<-data.frame(item=df$item ,user=df$user ,pref=df$pref )
keyval(key,val)
}
)
3. equijoin co-occurrence matrix and score matrix
1
2
3
4
5
6
7
8
9
10
11
12
eq.hdfs<-equijoin(
left .input =step2.mr,
right .input =train2.mr,
map .left =function (k,v) {
keyval(k ,v )
},
map .right =function (k,v) {
keyval(k ,v )
},
outer = c ("left" )
)
4. 計算推薦的結果
1
2
3
4
5
6
7
8
9
10
11
12
13
cal.mr<-mapreduce(
input=eq.hdfs,
map=function (k,v)
val<-v
na<-is.na(v$user .r)
if (length(which(na))>0 ) val<-v[-which(is.na(v$user .r)),]
keyval(val$k .l,val)
},
reduce=function (k,v)
val<-ddply(v,.(k.l,v.l,user.r),summarize,v=freq.l*pref.r)
keyval(val$k .l,val)
}
)
5 . output list and score
1
2
3
4
5
6
7
8
9
10
11
12
result .mr<-mapreduce(
input=cal.mr,
map=function(k,v){
keyval(v$user.r,v)
},
reduce=function(k,v){
val<-ddply(v,.(user.r,v.l),summarize,v=sum(v))
val2<-val[order(val$v,decreasing=TRUE ),]
names(val2)<-c("user" ,"item" ,"pref" )
keyval(val2$user,val2)
}
)
6 . result
Data preprocess
input: csv file (user,item,rating ex: 1,101,5.0)
實際資料:MovieLens Data Sets
GroupLens Research has collected and made available rating data sets from the MovieLens web site (http://movielens.umn.edu ). The data sets were collected over various periods of time, depending on the size of the set.
origin data sets MovieLens 10M - Consists of 10 million ratings and 100,000 tag applications applied to 10,000 movies by 72,000 users.MovieID index file
1
2
3
4
5
1 : :Toy Story (1995 ): :Adventure|Animation|Children|Comedy|Fantasy
2 : :Jumanji (1995 ): :Adventure|Children|Fantasy
3 : :Grumpier Old Men (1995 ): :Comedy|Romance
4 : :Waiting to Exhale (1995 ): :Comedy|Drama|Romance
...
format convert:
原始格式:UserID::MovieID::Rating::Timestamp
1
2
3
4
5
1::122 ::5 ::838985046
1::185 ::5 ::838983525
1::231 ::5 ::838983392
1::292 ::5 ::838983421
...
- 轉換格式:`UserID,MovieID,Rating` save as `movielen_dataset.csv`
1
2
3
4
5
6
7
8
9
f = File.open ("movielen_dataset.csv" , "w" )
File.open ("ratings.dat" ).each do |l|
temp = l.split ("::" )
userID = temp[0 ]
movieID = temp[1 ]
rating = temp[2 ]
f << "#{userID},#{movieID},#{rating}\n"
end
f.close
1
2
3
4
5
1 ,122 ,5
1 ,185 ,5
1 ,231 ,5
1 ,292 ,5
...
Result
…待補,vm localhost hdfs 跑好久
failed Reduce Tasks exceeded allowed limit
Reference